Omnio
Omnio is the first multimodal AI model to deeply understand conversations and human behavior through audio. It identifies speakers, roles, emotions, sentiment, and speaking styles, along with sounds and non-verbal cues, offering unparalleled auditory insight.

Product Description
Omnio is the first multimodal AI model that comprehensively understands both conversations and human behavior through audio. It excels in identifying speakers, their roles, and the nuances of interactions, including emotions, sentiment, and speaking styles. Omnio processes audio signals directly, enabling a deep understanding of the auditory environment. It also supports a range of industry-specific tasks and integrates into business workflows for real-world impact.
Core Features
- Deeply understands audio and conversations.
- Identifies speakers, roles, emotions, and speaking styles.
- Recognizes sounds and non-verbal cues.
- Performs on par with leading text AI models like GPT-4.
Use Cases
- Healthcare: Create medical documentation.
Pricing
- Omnio API offers $5.00 in free credits.
- Text input tokens: $2.00 per 1M
- Text output tokens: $5.00 per 1M
- Audio input tokens: $50.00 per 1M tokens
- Audio output tokens: $10.00 per 1M
Similar Products
Access to the Best-in-class AI models with the ability to compare them for the best outputs. Includes - ChatGPT, Google Gemini, Claude 3, Bing Copilot, Llama, Perplexity, Mixtral and 20+ more!

Just AI News is a media outlet where you can get the latest artificial intelligence news at Just AI News. We provide up-to-date information on AI technologies, company developments, and real-world applications.

The Worlds Most Powerful AI Tools at Your FingerTips. - AI BrowserCopilot - Access to 25+ AI Models and ability to compare them - AI Document Editor - AI Learning Companion

aceData AI is a powerful telemetry tool designed for simracers, delivering detailed performance insights in a simple, user-friendly interface. It provides real-time data on racing lines, throttle, and braking to help drivers improve lap times.

Verify and Check Fake Emails Effortlessly With The AuthentiCheck Spam Mail API. Our Reliable Tool Protects Your Inbox From Spam & Phishing Attempts. Try it Now!

Similarix adds AI to S3 buckets for semantic search, deduplication & more. It's secure (read-only), multilingual & easy to integrate. Search by text or image and organize better while keeping your costs low.
News, events, press releases and research articles about Web3, Metaverse, Blockchain, Artificial Intelligence, Crypto, Decentralized Finance, NFTs and Gaming. Web3Wire has been recognized as one of the Top 15 Web3 Blogs by Feedspot, with 50K+ monthly visitors and growing. We partner with Globe Newswire and PRNewswire, providing distribution for Web3 and crypto press releases. Our coverage includes major events like the Future Blockchain Summit 2024, India Blockchain Summit, and Blockchain Life.

I conduct live interviews using voice and text-based methods, evaluate in real-time, and present the best candidates for you.

Omnio is the first multimodal AI model to deeply understand conversations and human behavior through audio. It identifies speakers, roles, emotions, sentiment, and speaking styles, along with sounds and non-verbal cues, offering unparalleled auditory insight.

Secure AI for Teams - Save Time While Keeping Your Data Safe We prevent your data from leaking externally and internally. As a result, employees can safely use AI within your organisation fostering decisions making, collaboration and communication.

Predibase is a low-code AI platform that makes it easy for engineers and data scientists to build, optimize and deploy state-of-the-art models - from linear regressions to large language models - with just a few lines of code.

Zealos is an AI tool that delivers speed and accuracy for fact-checking. Save time and enhance credibility with effortless verification. Fact-check faster. Fact-check smarter. Fact-check with Zealos.

At Lyzr, we build Private Agent SDKs to help enterprises build 'fully-private' generative AI apps where the data does not leave their environment, without compromising the capability of the GenAI application.
Simba is an AI-powered landing page advisor that helps local service businesses optimize their conversion rates. Users can get tailored feedback by entering their landing page URL and selecting its goal. Simba evaluates the page against 16 best practice criteria to provide a comprehensive rating.
Wedding Speech Genie is an AI-powered platform that helps you create personalized wedding speeches in minutes. Whether you’re the best man, maid of honor, or father of the bride, our tool generates custom speeches tailored to your role and style.
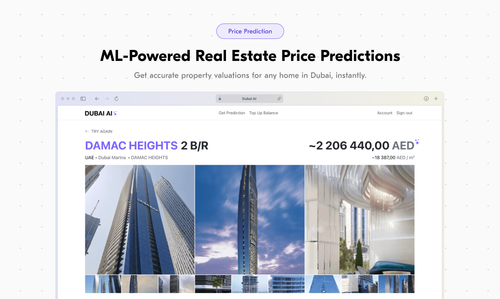
Dubai AI revolutionizes the real estate market in Dubai by harnessing the power of machine learning. Trained on millions of transactions, our AI predicts the market value of any property in Dubai based on key parameters such as location, size, amenities, and more. Dubai AI doesn’t just give a price — it explains the factors behind that price, making it easier for buyers to make informed decisions, sellers to set competitive prices, and real estate agents to communicate value to their clients.

Effortlessly create AI-powered websites and unlock new revenue streams! Access ready-made website templates or build your own with APIs. Whether you're coding-savvy or prefer plug-and-play solutions, our platform helps you monetize AI without hassle.
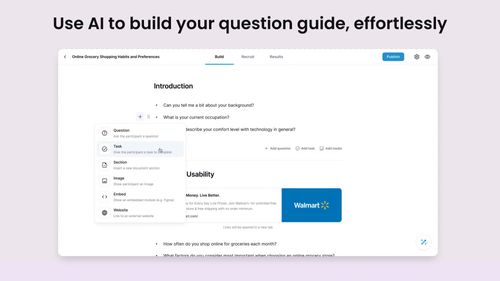
Strella is a customer research platform that uses AI-moderated interviews and real-time synthesis to deliver human insights at scale. Strella delivers insights 10x faster, turning weeks of research into hours and enabling smarter, faster decisions.

Abyss is a marketplace for AI solutions. It provides all the necessary tools for developers to seamlessly transform their code into user-friendly, AI-powered applications, allowing them to monetize their work while making AI accessible to everyone.

Dump your thoughts and discover the shape of your life.